Compilers are among the most important tools when it comes to software development. In a previous blogpost we argued that compilation speed is one of the key factors that influences the developer experience. We discussed a few ways of improving a compiler's efficiency, which is one of its most important selling points.
Modern compilers, however, are responsible for much more than just compilation. They can perform a variety of tasks which may escape the perception of the end user, but which nonetheless have a significant impact on the user's development process, and the quality of the final product.
What do we expect from a modern compiler?
While modern compilers usually offer a wide range of features, let's focus our attention on some of the most important ones that directly impact usability, performance, and developer experience.
Optimized and versatile code generation
Code generation is the process of transforming some representation of the program in the compiler into the final output — for example assembly code. The part of the compiler that performs this step is usually called compiler backend. In this step, or just before before it, compilers also perform most of the optimizations, that can make the program run many times faster.
First and foremost, if we want the speed of the generated code to be on par with what other compiled languages achieve, we have two choices: spend years writing countless optimizations by hand or, more practically for an emerging language, leverage an existing infrastructure like LLVM. Sadly, LLVM can't perform all possible optimizations for us, as it doesn't know the semantics of our language. To some extent, we can provide appropriate annotations which will cover many low-level optimizations, but for higher-level constructs we will likely have to implement them ourselves.
Secondly, of course, a modern, general-purpose language has to be portable. This brings us to another major challenge: generating machine code for countless existing architectures — a problem that we don't want to solve ourselves, as it would be a monumental task likely requiring constant maintenance. Instead, we can rely on LLVM, which already solves this problem for us. It provides a wide range of backends for different architectures, allowing us to generate machine code for various platforms without having to implement anything.
Fortunately,1 we can leave most of the code generation in LLVM's capable hands. Of course, these topics hide many details, but we will discuss them at another time.
Quick builds
We've already written at length about compilation speed in a previous article. For the purpose of this post, let's do a quick recap.
Compilation speed may be influenced by many qualities of the codebase. These include: total project size, file size distribution, usage frequency of compiler-heavy features of the language (e.g. templates in C++), number of dependencies, and so on. The hardware also plays a role — we may run on a powerful, distributed server or on an old laptop. Regardless, the biggest factor is the speed of the compiler itself. This creates another big challenge to solve when writing a compiler — it has to be efficient.
One of the most important aspects of compilation speed is specifically the speed of subsequent compilations. Compiling unmodified or minimally modified code should be much faster than running a clean build. After all, it would be nice if we didn't have to recompile the entire codebase after changing just a single line. This turns out to be quite a difficult problem to solve.
Our compiler should be reasonably performant for most codebases and in most scenarios. There are many ways to achieve this, but the general idea is that we should do as little work as is actually needed while using all the resources we have available. Some methods of achieving this involve incremental, lazy, and multithreaded compilation. However, it is not always clear how we would go about optimizing more complex operations, such as evaluating constants during compilation.
Good error messages
Error messages are a key part of the developer experience, as they are the primary channel of communication between the compiler and the programmer. Good errors should be clear, concise and provide enough information to the programmer so that they can understand what went wrong and fix the issue.
It is however extremely hard to actually generate good error messages in some contexts, as it may be very hard to guess what information will be useful to the user, and which will only distract from the problem. In Duckling, we go a step further, working on an interactive error messages system, that is actually only feasible thanks to the Query Framework we employ (we will get to what it is soon!).
Integration with IDEs and other tools
When writing code, we use more tools than just the compiler, e.g. linters, formatters, debuggers, profilers, etc. Most notably, the Language Server is a tool that provides functionalities in the IDE like code highlighting, code completion or go-to-definition. Usually, the Language Server communicates with the IDE through the Language Server Protocol (LSP). For example, if we want to peek the definition of a symbol, the IDE will use LSP to ask a Language Server where the symbol is defined.
Many queries are handled by the Language Server itself (partially because calling the compiler each time would be too slow), but there are some that are aided by the compiler. For example, displaying compilation errors or performing automated refactoring may require semantic information about the code only available to the compiler. Similar scenarios can happen in other tools: debuggers often require linking compiled code with the source, and profilers need additional instrumentation in the generated program. This generates the need to write the Language Server and add a layer of communication between it and the compiler, which makes the whole system more complicated.
Understating and Analyzing the Language Semantics
Handling semantics is perhaps the most obvious task of a compiler — it has to parse and analyze the language, as this is what compilers do. This in itself is quite a difficult task, especially when the language supports many not-so-straightforward features like an advanced type system, procedural macros, templates, or compile time evaluation. It turns out, however, that it is the architectural design of a compiler that places some limitations on what language features it can realistically support.
So, let's take a look at how a typical compiler works.
A typical compiler
Usually, the compilation process is split into distinct stages: lexical analysis, syntax parsing, semantic analysis, intermediate optimization stages, and finally code generation and linking. This pass-based architecture has been the standard for decades, originally driven by limited memory resources, as it allows compilers to process code almost in-place.
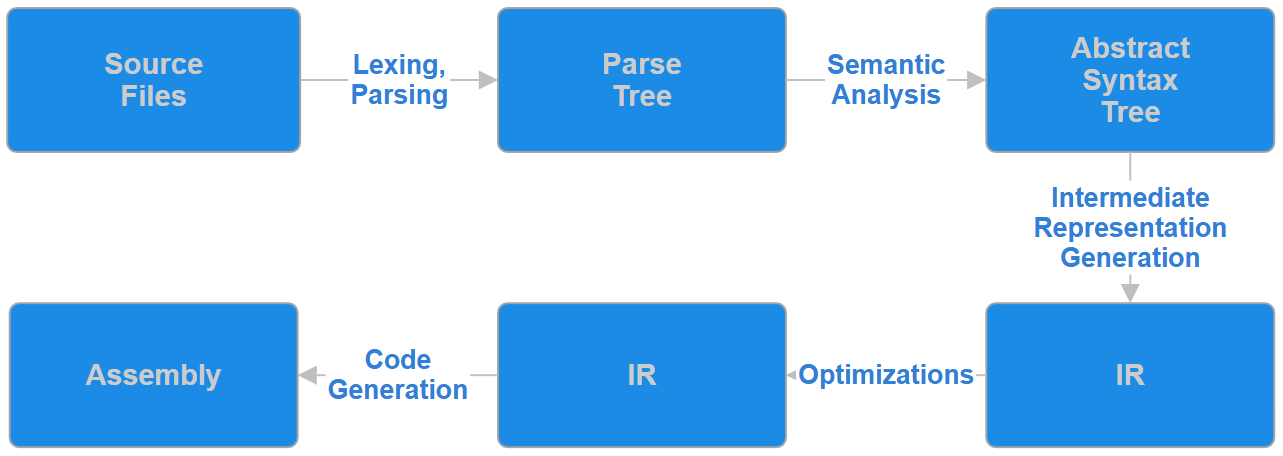
Unfortunately, this approach has some inefficiencies and limitations. Each pass generally requires scanning and processing the same parts of the source code multiple times. It's also not well suited for incremental compilation, as we can only easily store the results of entire passes. Fine-grained control over what needs to be recompiled requires additional work.
Another interesting challenge for this architecture are cyclic dependencies between compilation stages.2 An example would be a situation where we need to know a type of some symbol to parse another code construct. More generally, problems arise when we need to run the code during compilation (so called compile-time evaluation), for example to evaluate types or constants.3 Today, this is usually done by simply performing single operations directly on the Abstract Syntax Tree, or similar higher-level representations of the code.
fun generateType() -> type = {...}
var x: generateType();
x.performTask();
Going through and evaluating each node one by one is usually quite slow, but it works and is relatively easy to implement. There are some possible optimizations, like lowering loops to a more efficient form before running them, but this approach is far from optimal when there is a lot of code to run. Ideally, we would like to compile the relevant sections to machine code or some other low-level representation (e.g. Virtual Machine bytecode) and execute them. This would normally introduce a lot of additional complexity,4 but it just so happens that we already have a VM (developed mainly for debugging purposes) that we could use for this task.
Another potential problem of the pass-based architecture may be the lack of clarity in error messages. This issue is particularly pronounced in the later stages of compilation, especially if the errors are context-dependent and some context has already been discarded by the compiler. This may be minimized by keeping more context information in the later stages, but this may lead to increased memory usage and slower compilation times. A clever solution would be to simply query only the information we need, only when we need it.
There is also a drawback to this architecture when it comes to interactions with other tools, like Language Servers. Said interaction typically boils down to a single call to the compiler with the right flags, and parsing the compiler's output. This means that if the needed information is present in some pass of the compilation, all previous passes have to be fully completed. As a result, typical compilers have to perform a lot of time-consuming work, and since their incremental capabilities are limited, calling them for most tasks is very expensive, making it generally not a viable option. This also means that some work may be duplicated by the compiler and the Language Server, although some tool collections like GNU and LLVM can share common parts between different tools and make it possible to reuse some results. Here again, it seems that instead of invoking the entire compiler, it would be nice to only call some smaller part of it, throught some kind of API, to compute and return only the information we need.
The new architecture
The problems described above are not new. The developers of mature compilers have already spent a lot of time finding ways to mitigate them, since the general architecture of compilers has not changed much in the last few decades. Ideas such as incremental compilation, parallel compilation and advanced intermediate representations are just a few of the techniques that were developed to address these issues. They however are not easy to implement. For example, there was a project to turn GCC into incremental compiler, but it ultimately didn't achieve its goals and was suspended.
Today, we see other advanced solutions like clang's constant interpreter project emerge. However, many remaining limitations are related to the compiler architecture itself, and because of this it is hard to make significant improvements. The Rust compiler had gone through multiple iterations before they managed to achieve stable and performant incremental compilation. In the end, it turned out to be possible only when they changed how the fundamental architecture of the compiler works.
Let's recount how our team stumbled upon similar a solution.
Our problems
In the early stages of developing the frontend for our compiler, we realized that some features we wanted to implement would require going through the compiler pipeline multiple times. These were primarily features like macros and templates, which, after expansion/substitution, would need rerunning at least some stages of the compilation process. In the pessimistic case, those could recursively expand new macros or templates, which would require repeating compilation passes multiple times, potentially leading to significant slowdowns. What we wanted was a relatively lightweight way to call a part of the previous compilation stages without rerunning the entire pipeline and without having to reimplement the logic of the stages we wanted to call.
At first, we came up with the solution that was based on lazy compilation (an idea of performing certain compilation steps only when we really need them), and interleaving compilation passes with each other, running them independently for each element of the code (functions, namespaces, etc). After some research, we found that what we were trying to do was essentially a form of demand-driven compilation,5 which is a relatively new approach to building compilers. One notable compiler using this architecture is, mentioned before, the Rust compiler.6
The Query Framework
The general idea is pretty straightforward — we replace the stages of the compiler with a large collections of small queries.7 Each query is basically a (mostly) pure function responsible for a single task in the pipeline, such as getting the type of a symbol or performing a name lookup. As a result, queries remain relatively small and are only executed on demand, making it possible to rerun parts of the pipeline efficiently. But it turns out that this model has numerous other benefits as well. It's probably not hard to guess that since queries are pure functions, they can be easily memoized, which for example fits very nicely with our goal to support incremental compilation. Let's take a look at how this works in practice. Consider the following code fragment:
let x = 1;
fun foo(a: i64) = {
return x + a;
};
fun foo(a: f64) = {
if (a > 0.0) return 1.0;
else return 0.0;
};
let y = foo(x);
The part of the compilation graph responsible for determining the type of the variable y could look something like this:

Before we consider all the pros and cons of this approach, let's take a quick look at the (slightly simplified) usage of the query framework in our compiler. The framework is not very complicated — each query consists of three functions: provide which performs the actual computation, store which is responsible for caching the provided result and returning a handle to it, and load which checks if the result is already cached and retrieves it if it is. The framework also, among other things, automatically tracks dependencies between queries, detects cycles between them and provides a standardized way to handle errors.
We are implementing our compiler in C++, and since reflection is not available yet and will probably take some time to receive proper support, we unfortunately have to rely on macros to avoid boilerplate. To declare a query we simply use DECLARE_QUERY and pass the Name of the query, the Key type and the Result type. To implement it we use IMPLEMENT_QUERY like so:
// in the header:
DECLARE_QUERY(QueryName, Key, Result);
// in the source file:
struct IMPLEMENT_QUERY(QueryName, Result) {
// here we implement the provide, store and load functions:
auto provide(..., Key key) -> Result {...}
// ...
};
QUERY_IMPLEMENTATION_BOILERPLATE(QueryName);
The provide method is essentially just a normal function that performs a given computation. The load and store functions can usually be automatically generated by the framework. This means that in most cases, writing a query requires almost the same amount of work as writing a normal function would.
Pros
We have already mentioned some of the benefits of the query framework, but let's summarize them here.
First of all, queries keep things clean — they are not only an abstract concept but a real framework. The Query Framework encourages a clean implementation approach and enforces concrete requirements regarding the queries. In essence, it is a model that formalizes how certain components of the compiler work and cooperate. This allows us to automate a lot of tasks that would otherwise be exceptionally difficult, like tracking dependencies between query calls. On top of that, the fact that queries are in a way pure functions, means we can gain a lot of benefits that are usually present in functional programming. We can, for example, call any query wherever we need without any concern for the global state of the compiler or compilation stages.
The Query Framework is the backbone of incremental compilation in both the Duckling and Rust compilers, without which the same level of accuracy and performance would not be possible. The Duckling compiler also uses the Query Framework to standardize and automate how compilation errors are handled, solving a lot of problems with minimal effort and code bloat (in the next article we will talk about this in greater detail). It also allows us to develop some more advanced functionalities, such as the previously mentioned interactive error inspection.
The framework also allows for much better IDE integration — the compiler can basically serve as the Language Server, which can call queries to get the information it needs. It is only possible because each query performs only the tasks it really needs to, meaning that the compiler can answer IDE requests much faster. This removes the need to write a separate Language Server with its own internal logic — the Language Server becomes a simple layer that translates IDE requests to compiler queries. It even allows for more complex features that would otherwise be too expensive to run with the traditional architecture, like the previously mentioned interactive errors.

x will invalidate (red) the query looking it up and may or may not (orange) change the results of other queries, but it will not affect (green) the lookup of foo for the purposes of, for example, autocomplete.We can also efficiently evaluate constant expressions (with the support of our VM) and efficiently compile complex language features like macros and templates. Additionally, we benefit from starting with this design early on, because we can anticipate and avoid many problems that could otherwise arise and, for example, prohibit some language features.
Furthermore, it turns out that it's possible to parallelize the compilation process that uses the query framework. Of course, the simplest step is to run the compilation of separate modules in parallel. The query framework however gives hopes for much better approach, in which we run multiple queries in parallel within a single module. This is far from simple, and we haven't implemented it yet, but we have a pretty good idea of what should be possible. We are heavily inspired by this paper, which has many good ideas on how to concurrently detect changes, keep consistent query caches and detect cycles.
Cons
Of course, there are some downsides to the Query Framework. Since we have to stick to the model, it may introduce some limitations, though with how general and extensible the model is, this isn't a serious threat. Arguably simple queries are burdened with quite a bit of boilerplate, but complex ones are better organized thanks to the framework. Obviously, there is also a small overhead for clean builds,8 as we may keep more state than a standard pass-based compiler and hence use more memory, especially for large projects.
Another downside is that true cyclic dependencies in queries are a new type of error that the users of our language will have to deal with. This occurs when the compiler encounters a cycle of query calls while attempting to evaluate some query. For example, consider the following code:
class Type {
val: Type;
}
In this example, the type definition is self-referential. Of course, this problem is not new in programming languages. What is new here is how the compiler may report such an error. Instead of pointing directly to the self-referential code, the error message may indicate a cycle in the query system, requiring the programmer to analyze a chain of dependencies, which can be harder to comprehend and debug. In simple cases like the one above, the compiler will likely be able to figure out the problem and provide a more precise error message, but in more complex cases with longer query cycles, it may be much harder to find the root cause.
Conclusion
The Query Framework seems to be a promising architecture for our compiler. It allows for better support for both incremental and parallel compilation, and provides a much better way to interact with the compiler for other tools, such as IDEs. Combined with our VM, it allows for efficient evaluation of constant expressions and efficient compilation of complex language features like macros and templates. Downsides seem to be manageable and we think that the benefits clearly outweigh them.
-
Or perhaps unfortunately, as these topics are quite interesting. ↩
-
There is an interesting paper on this topic which you can find here. It goes into details, describing the authors' own version of the Query Framework. ↩
-
Types and values are actually treated in Duckling as one and the same thing. There will be a post about this soon! ↩
-
As far as I know there are no production-grade compilers that evaluate things during compilation with an interpreter, but there is an experimental project for clang that introduces a constant interpreter which aims to interpret compiled bytecode replacing the current AST evaluator. ↩
-
The topic is quite new, but already a lot of research was invested into it. The earliest work we found that talks about demand driven compilation (in context of incremental compilation) was a paper from PLDI 2014 titled ADAPTON: Composable, Demand-Driven Incremental Computation. It didn't talk about the idea in terms of queries but it introduced a lot of concepts which correspond to query frameworks from Rust or Duckling compilers today. ↩
-
Description of demand-driven compilation based on queries in Rust compiler ↩
-
Conceptually we still recognize individual compilation stages, but we don't implement them as single passes. ↩
-
Concerete numbers are hard to come by, as there exist few languages for which there are both pass- and query-based compilers. There is a tracking issue for incremental compilation in rustc which lists individual issues improving Framework Overhead but it doesn't provide benchmarks. In the article Parallel Query Systems we can find frontend benchmarks of Go's compiler (pass-based) and the Haste compiler developed for this paper (query-based), but the direct comparison between them would not be fair as they do not perform the same tasks (Haste does not perform code generation) and are written in different languages — Go's is implemented in Go, while Haste is in Rust. ↩
